Transcription and Translation as a Service (TTaaS) Manifest¶
Service can be accessed at: https://ttaas.web.cern.ch.
Aims¶
TTaaS provides an automated on-premise “transcription and translation” service at CERN.
Main aims of the service are:
- Providing Automated Speech Recognition with a Word Error Rate (WER) <20% within the complex technical vocabulary and mixed accents of CERN presenters (please see below the final results of our collaboration with MLLP, research team that won the tender process DO-32939/IT)
- Providing a translation in French with a BLEU above 40
- Processing the entire video collections of CDS Videos, Academic Training lectures, Digital Memory and ATLAS, comprising more than 30,000 hours of recordings. This will equip our rich collection with subtitles and translations. In addition, all newly created material (estimated at 2300h/year of offline workload) will also have subtitles and translations made available by default, either reviewed by a designated editor or published automatically. The spoken words will then become searchable in our collections, a ground-breaking change which will multiply the potential of CERN’s media archives in several ways.
- Automated live transcription (estimated in 1300h/year of online workload) and highly accurate captioning of high-profile Zoom events and Webcasts (Work In Progress).
- The service is mainly focus on English and French languages for the time being.
The service is underpinned by GPU power (at this time NVIDIA Amper technology) provided by CERN openstack. Our capacity to deliver offline and online is dependent on it. For the time being we can provide offline transcriptions with an RTF (real time factor) of 0.4 (A100 Nvidia GPU cards) and online transcript with a latency < 1.1 seconds, please see below table.
WER comparison of actual new model CERN-Mai24 with previous model CERN-Nov22 and with Whisper in its large representation (new cern-mai24 was released about 15 July 2024, so comparative is around that date):

Further details can be found at D3.6: Final development, deployment and testing of the Solution.
Offering¶
For offline, the service offers a Web User Interface (WebUI) and a API in order to tranfer/upload/query media resources (audio and video) and download the obtained results.
The service interface to CERN apps/services is the same. This implies an agnostic view as internal workflows should be unaware of how those user application/services internally work. Please check our swagger API description - from CERN network for more details.
Any request that differs from mainstream are simply not maintaneable and therefore not possible. The service will try to keep up-to-date with upstream versions. The service is powered by Machine Learning and Language processing (MLLP) engine.
Details on the online part of the service can be found here: CERN online ASR
How I can use the service?¶
The service clients should open a Snow Ticket to provide the folowing information, in order to use the TtaaS WebUI and API:
- One existing CERN USER principle or SERVICE account capable of login into the SSO to get the required permissons for using the WebUI.
The user can create his/her own access tokens to the API.
The client is reponsible for the upload of his/her source files and download of thes resulting files. Nowadays we have a limitation on terms of media size it should be less than 2GB and in terms of audio length it should be less than 6 hours. In general users tend to upload mp4 but other format files are also supported:
| Type | Formats |
|---|---|
| video | mp4, m4v, ogv, wmv, avi, mpg, flv, mov |
| audio | wav, mp3, oga, flac, aac |
Please do contact us if you are missing a format.
Those files will be available in the server for downloading during a limited period of time, mainly for purpose of edition. This period is fixed nowadays to 6 months.
The service is running on CERN openstack virtual machines. It's limited on the resources that such virtualization is offering. As resources are shared, no priorities will be stablished for specific tasks. The architecture of the framework does allow to scale the service, if computing power is available.
Architecture¶
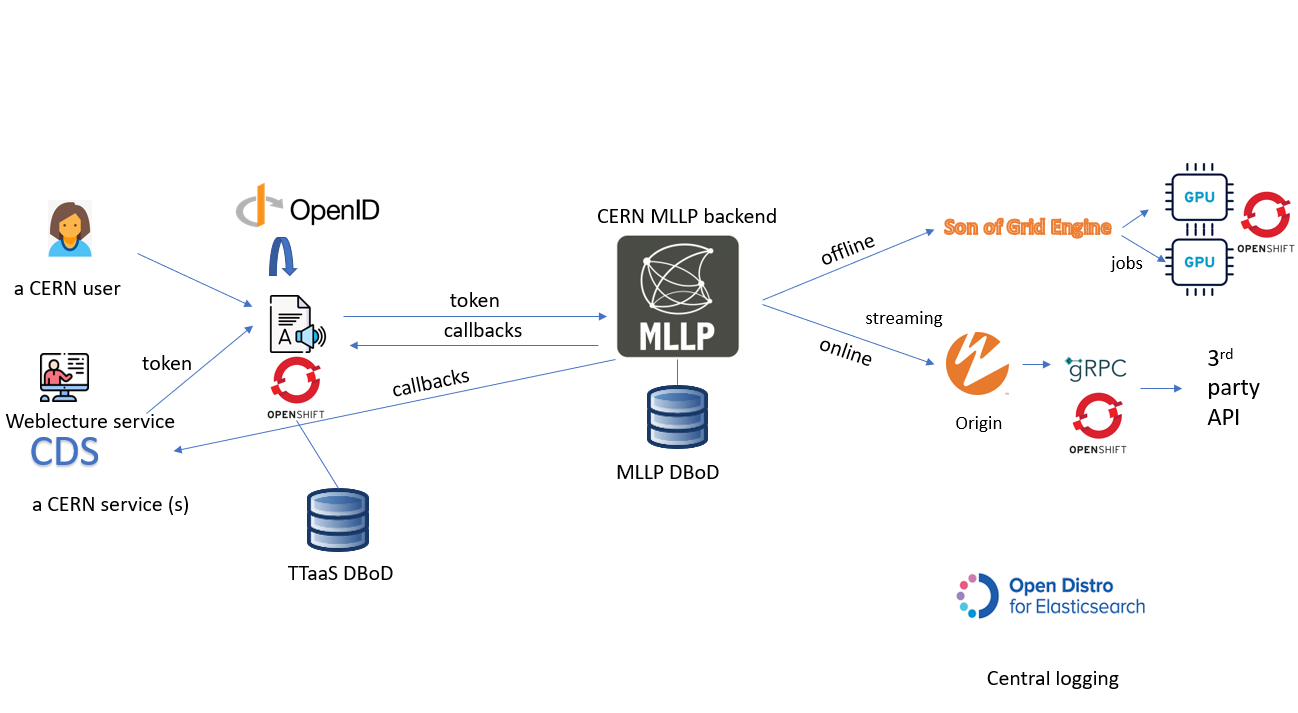
This is a simplified overview of the TTaaS. The service can be accessed either a normal CERN user (with a primary account) or an other CERN service like: CDS/Videos or Weblecture service. One you have been authenticated, authorization for the different actions e.g. ingesting, editing, retrieving an srt or vtt can be performed either in the WebUI or programatically via REST API calls and callbacks. Please check the different sections of the website for more details.
Nowadays two uses cases are considered:
- offline: jobs are ingested and sent to our on-premise MLLP backend which forwards them to our cluster manager that process them on different VM's with GPU power at CERN Openstack
- online: an stream needs to be pushed to our GRPC server. Nowadays our use case is Zoom, so Zoom streams to Wowza that connects to our GRPC server that uses MLLP online decoders to get the transcripts/translation and it sends them back to the application via an API.
All components log into a CERN opendistro instance.